Các kiểu số nguyên của c# và .net
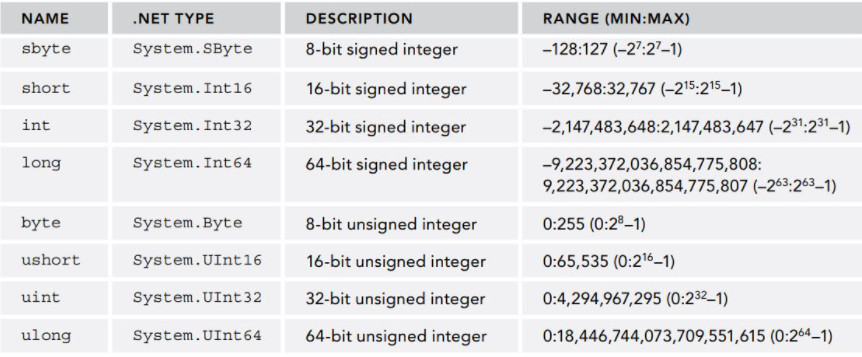
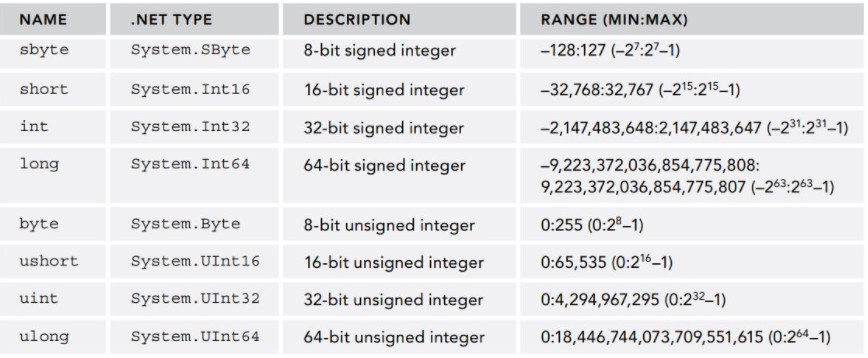
Như bạn đã thấy trong bảng trên, C# (và .NET) cung cấp 8 kiểu số nguyên, phân biệt ở số byte để biểu diễn và vùng giá trị. Tên của các kiểu này hoàn toàn giống như trong Java hay C++. Cách sử dụng cũng hoàn toàn tương tự. Tuy nhiên có những điểm khác biệt cần lưu ý.
int và byte
Kiểu int của C# luôn luôn chiếm 4 byte (32 bit). Trong C++, số bit của kiểu int thay đổi phụ thuộc vào platform (vd, trên windows là 32 bit).
Kiểu byte là 8 bit, có dải giá trị từ 0 đến 255, và không thể chuyển đổi qua lại với kiểu char như trong C. Kiểu byte luôn luôn không dấu (khác với C). Nếu muốn sử dụng số nguyên 8 bit có dấu, bạn phải dùng kiểu sbyte.
Cơ số
Tất cả các kiểu số nguyên đều có thể nhận giá trị biểu diễn ở nhiều cơ số (base) khác nhau: cơ số 10 (decimal), 16 (hex), 8 (octal), 2 (binary). Giá trị biểu diễn ở các cơ số khác 10 phải sử dụng thêm tiếp tố (prefix) tương ứng.
long x = 0x12ab; // số hexa, prefix là 0x hoặc 0X
byte y = 0b1100; // số nhị phân, prefix là 0b hoặc 0B
int z = 01234; // số hệ cơ số 8, prefix là 0
Digit separator
C# 7 cho phép sử dụng dấu _ giữa các chữ số để tách các chữ số cho dễ đọc hơn với các giá trị lớn. Dấu _ gọi là digit separator.
long l1 = 0x123_456_789_abc_def; // dấu _ giúp tách các chữ số cho dễ đọc
long l2 = 0x123456789abcdef; // cách viết thông thường
int bin = 0b1111_1110_1101; // viết tách các bit thế này dễ đọc hơn
Integer literal
Khi dùng từ khóa var để khai báo biến thuộc kiểu số nguyên, C# mặc định sẽ hiểu nó là kiểu int. Nếu muốn chỉ định giá trị nguyên thuộc một kiểu nào đó khác, bạn phải sử dụng một cách viết riêng gọi là integer literal.
Integer literal là các ký tự viết vào cuối giá trị số (postfix) để báo hiệu kiểu dữ liệu, bao gồm: U (hoặc u) báo hiệu số nguyên không dấu; L (hoặc l) báo hiệu giá trị thuộc kiểu long; UL (hoặc ul) cho kiểu ulong. Có thể sử dụng các ký tự này khi viết ở hệ cơ số khác 10. Ví dụ:
var i0 = 123; // c# mặc định coi đây là kiểu int
var i1 = 123u; // giá trị này thuộc kiểu uint
var i2 = 123l; // giá trị này thuộc kiểu long
var i3 = 123ul; // giá trị này thuộc kiểu ulong
var i4 = 0x123L; // giá trị kiểu long ở hệ hexa
Từ giờ về sau bạn sẽ còn gặp nhiều literal nữa. Literal (chính tả) là cách viết giá trị của từng kiểu dữ liệu.
Nếu bạn khai báo số nguyên có giá trị đủ lớn để thoát khỏi dải của int, C# sẽ tự chọn kiểu phù hợp có dải giá trị đủ bao trùm. Ví dụ:
var ui = 3000000000; // đây sẽ là kiểu uint
var l = 5000000000; // đây sẽ là kiểu long
Các kiểu số thực
C# (và .NET) chỉ cung cấp 2 loại số thực: float (System.Single) và double (System.Double). Các thông tin chi tiết bạn đã xem ở phần trên. float có dải địa chỉ nhỏ hơn và độ chính xác thấp hơn so với double.

Các kiểu số thực của C# và .NET
Khi dùng từ khóa var với giá trị số thực, C# sẽ mặc định hiểu nó thuộc về kiểu double. Để chỉ định một giá trị thực thuộc kiểu float, bạn cần dùng postfix F (hoặc f) sau giá trị. F (hoặc f) được gọi là float literal.
var r1 = 1.234; // r1 thuộc kiểu double
var r2 = 1.234f; // r2 thuộc kiểu float
decimal (System.Decimal) là một dạng số thực đặc biệt chuyên dùng trong tính toán tài chính.
Kiểu decimal của C# và .NET
Literal cho decimal là M (hoặc m).
var d = 12.30M; // biến này thuộc kiểu decimal
Các kiểu số thực cũng hỗ trợ cách viết dạng khoa học (và có thể kết hợp với float decimal):
var d1 = 1.5E-20; // cách viết khoa học bình thường là 1,5*10^-20, kiểu double
var f1 = 1.5E-10F; // số 1,5*10^-10, kiểu float
var m1 = 1.5E-20M; // 1,5*10$-20, kiểu decimal
Kiểu Boolean
Boolean (.NET) hay bool (C#) chỉ nhận đúng hai giá trị: true và false. Đây cũng được gọi là literal của kiểu bool.

Kiểu logic bool của C# và .NET
Trong C# không thể tự do chuyển đổi giữa bool và số nguyên như trong C/C++. Tức là bạn không thể sử dụng 0 thay cho false, giá trị khác 0 thay cho true như trong C. Biến khai báo thuộc kiểu bool chỉ có thể gán giá trị true hoặc false.
Kiểu ký tự
Kiểu char (C#) hay System.Char (.NET) dùng để biểu diễn ký tự đơn, mặc định là các ký tự Unicode 16 bit.

Kiểu ký tự của C# và .NET
Character literal
Literal của kiểu char là cặp dấu nháy đơn. Ví dụ ‘A’, ‘a’, ‘1’, ‘@’.
var c = 'A';
Đừng nhầm lẫn với cặp dấu nháy kép – là literal của chuỗi ký tự. Nếu sử dụng lẫn lộn cặp nháy đơn và nháy kép, compiler sẽ báo lỗi hoặc hiểu sai ý định của bạn.
Bạn cũng có thể sử dụng mã Unicode của ký tự như sau: '\u0041', '\x0041'.
var c1 = '\u0041';
var c2 = '\x0041';
Một cách khác nữa để biểu diễn ký tự là dùng mã decimal cùng với ép kiểu: (char) 65.
var c3 = (char) 65;
Escape sequence
Tương tự như C, C# cũng định nghĩa một số ký tự đặc biệt gọi là escape sequence:
- \’: dấu nháy đơn
- \”: dấu nháy kép
- \\: dấu backslash (dùng trong đường dẫn)
- \0: Null
- \a: cảnh báo (alert)
- \b: xóa lùi (backspace)
- \n: dòng mới
- \r: quay về đầu dòng
- \t: dấu tab ngang
- \v: dấu tab dọc
Kiểu chuỗi ký tự
Chuỗi (xâu) ký tự (string hoặc System.String), khác biệt với các kiểu dữ liệu bên trên, là một kiểu dữ liệu tham chiếu (reference type) . Trong khi các kiểu dữ liệu ở bên trên thuộc loại giá trị (value type). Sự khác biệt là gì bạn xem ở phần cuối bài.
Literal của string là cặp dấu ngoặc kép:
var str1 = "Hello world";
var emptyStr = ""; // đây là một chuỗi ký tự hợp lệ, gọi là xâu rỗng
Trong chuỗi ký tự có thể sử dụng ký tự escape sequence (bạn đã biết ở trên):
// chuỗi này chứa hai escape sequence \r và \n.
// nếu in ra console, con trỏ văn bản sẽ chuyển xuống đầu dòng tiếp theo
string message = "Press any key to continue\r\n";
Console.WriteLine(message);
// nếu in chuỗi này ra sẽ thu được x1 = 123 x2 = 456, tức là có 1 dấu tab ở giữa
string solutions = "x1 = 123\tx2 = 456";
Console.WriteLine(solutions);
Trong chuỗi không được có mặt ký tự \ (backslash). Lý do là ký tự này được sử dụng trong escape sequence. Ví dụ, dưới đây là một chuỗi sai (bị báo lỗi cú pháp):
string path = "C:\Programs\Visual Studio"; // chuỗi này bị lỗi vì chứa ký tự \.
Nếu muốn viết ký tự \ vào chuỗi, bạn phải viết nó hai lần:
string path = "C:\\Program\\Visual Studio"; // chuỗi này OK
hoặc thêm ký tự @ vào đầu chuỗi. Ký tự @ sẽ tắt chế độ diễn giải escape sequence.
string path = @"C:\Program\Visual Studio"; // chuỗi này OK vì ký tự @ sẽ tắt chế độ nhận diện escape sequence
Trong chuỗi ký tự cũng có thể chứa biến và biểu thức. Các giá trị này được tính toán trước khi chèn vào đúng vị trí của nó trong chuỗi. Tính năng này có tên gọi là string interpolation. Interpolated string được bắt đầu bằng ký tự $.
int x1 = 123, x2 = 456;
string solution = $"x1 = {x1} x2 = {x2} x3 = {x1 + x2}"; // đây là một interpolated string
Console.WriteLine(solution);
// nếu in ra console sẽ thu được x1 = 123 x2 = 456 x3 = 579
String interpolation là tính năng rất tiện lợi để tạo ra các xâu động từ biến và biểu thức.
Xâu là một loại dữ liệu đặc biệt và được sử dụng rất rộng rãi. Nội dung trong bài này chưa đủ để làm việc với xâu. Bài giảng này có bài học riêng về cách sử dụng xâu trong C#.
Kiểu object
object (System.Object) là kiểu dữ liệu đặc biệt trong C# và .NET. Nó là kiểu dữ liệu “tổ tiên” của mọi kiểu dữ liệu khác (root type). Đây cũng là một trong hai kiểu reference.
Bạn có thể hình dung như thế này. Trong các ngôn ngữ lập trình hướng đối tượng, các kiểu dữ liệu thường được tổ chức theo dạng phân cấp (hierarchy) như một cái cây. Trong đó kiểu dữ liệu cấp cao nhất, ở gốc của cây gọi là root type. Tất cả các kiểu còn lại đều là các nhánh xuất phát từ gốc. Nếu bạn hiểu khái niệm kế thừa thì object chính là tổ tông của tất cả các loại kiểu. Nói cách khác, mọi kiểu dữ liệu khác đều là con/cháu/chắt/chút/chít của object.
Chúng ta sẽ quay lại kiểu object khi học về class và kế thừa. Tạm thời bạn chỉ cần biết vậy là được.
Tuy nhiên có một phương thức quan trọng của object bạn cần biết: ToString(). Phương thức này có mặt trong mọi kiểu dữ liệu mà bạn đã biết (do cơ chế kế thừa từ object). Nó giúp chuyển đổi giá trị của kiểu tương ứng về chuỗi ký tự. Bạn sẽ thường xuyên cần đến nó khi viết giá trị của một biến ra console.
var a = 123.456; // a thuộc kiểu double
var strA = a.ToString(); // strA giờ là một chuỗi, có giá trị "123.456"
Phân loại kiểu dữ liệu trong C#
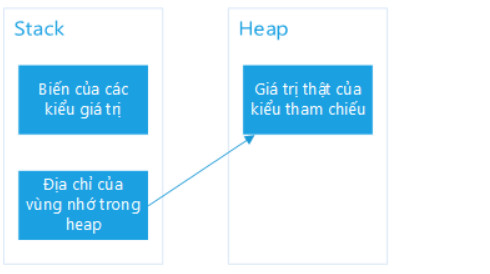
Stack và Heap
Để hiểu được cách thức phân loại kiểu dữ liệu, bạn cần nhớ lại một số vấn đề liên quan đến stack và heap.
Stack và heap đều là các vùng bộ nhớ trong RAM của máy tính nhưng được tổ chức và sử dụng cho các mục đích khác nhau.